By Sarosh Petkar, Malware Analyst, Barkly
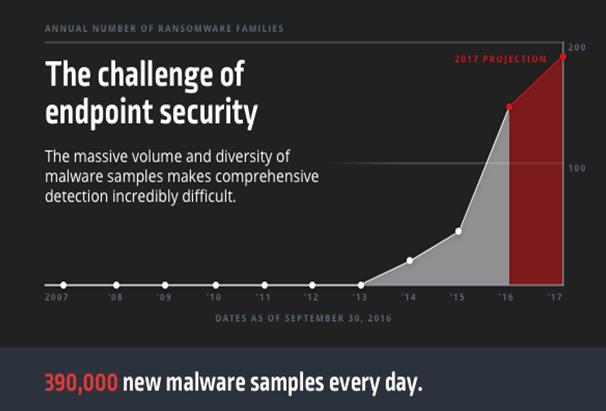
For years, we’ve heard the same things over and over again about the challenge of cybersecurity. Attackers will always be one step ahead of organizations. The amount of malware they’re producing is overwhelming and increasing every day. Compromise is inevitable.

But with the adoption of machine learning, security technologies are providing organizations with new ways to tackle this seemingly intractable problem. Models can process extremely large datasets and be trained to identify similarities in malware samples that make them distinct from good software. Retraining the models can also be automated to keep pace with the massive influx of new and changing samples that overwhelm traditional solutions.
There are, however, a couple of caveats that present challenges to machine learning, and limit the level of accuracy these models can achieve.
● Caveat #1: Models need to be trained on the right data: To accurately differentiate between malware and “goodware,” a model’s datasets need to consist of a diverse range of both. Otherwise, imbalances in sample types can produce biases. Ex: Models can be prone to false positives, classifying legitimate programs like malware and creating the need for overrides. This is especially true when organizations deploy their own or custom-built third-party software.
● Caveat #2: Models need to be constantly refreshed: Attacks evolve. New techniques and new malware appear constantly. As a result, as time passes, machine learning models designed to detect malware gradually deteriorate. Their accuracy suffers, with new malware samples slipping past them and updates to legitimate software triggering false positives. To compensate, some vendors use whitelisting and blacklisting, which increases management costs and doesn’t solve the underlying problem. It’s not until a model can be retrained on new samples that accuracy can be restored. And then the cycle begins anew.
With these caveats in mind, it’s worth noting the adoption of machine learning for security purposes is still in its early stages. As analysts point out, many models lack refinement and currently serve as “coarse-grained filters” that operate with a clear over-sensitivity to malware versus goodware. That’s because the vendors behind them have often found themselves facing a difficult choice between providing wider coverage (blocking more malware) or more accurate coverage (making sure malware is the only thing getting blocked). In those cases, wider coverage wins nearly every time. As a result, false positives have become the accepted price of protection, even though they are well understood to be a prohibitive barrier to effective roll-out and come at considerable cost.

As more security vendors turn their attention to successfully harnessing machine learning, however, significant advances are being made that may eventually make that “necessary” sacrifice a thing of the past.
A different approach that increases accuracy
To maximize coverage and accuracy, the approach to machine learning we take at Barkly involves nightly training of our models (which keeps protection up-to-date) as well as the creation of organization-specific models trained against each company’s unique software profile. Not only does that allow our models to be more current and responsive to the newest threats, but it also allows them to be less reactive to the legitimate goodware deployed in each environment.
Here’s how it works: Each night, we collect thousands of samples of new malicious software, and we combine those samples with up-to-the-minute data on the known-good software organizations are running. We then re-train and redistribute the updated models, which have been tailored and optimized specifically for each organization. Thanks to that cadence, we’re able to provide more accurate, maximized protection that maintains its strength over time.
We believe this new, responsive approach represents an exciting step forward in the way security providers can apply machine learning. But the truth is we still have a very long way to go before we tap the technology’s full potential. As adoption of machine learning becomes more prevalent we’re eagerly anticipating more breakthroughs that tip the scales against attackers.
About the Author
 Sarosh Petkar is a BS/MS student of the RIT Computing Security department. He is currently working as a Malware Analyst at Barkly, the Endpoint Protection Platform that delivers the strongest protection with the fewest false positives and simplest management.
Sarosh Petkar is a BS/MS student of the RIT Computing Security department. He is currently working as a Malware Analyst at Barkly, the Endpoint Protection Platform that delivers the strongest protection with the fewest false positives and simplest management.
His interests include reverse engineering, network security, and cryptography.
He can be reached online at [email protected].
