
The AI revolution has transformed how organizations operate, yet beneath the excitement of chatbots and autonomous agents lies a security crisis that most technology leaders are only beginning to comprehend. The threat isn’t theoretical. It’s happening right now, with real-world impacts such as leaking source code.
To understand the true scope of this challenge, we designed a global research experiment that would reveal how vulnerable AI systems are in practice and how security guardrails can reduce the risk of attack. We created a $10,000 global prompt injection challenge, offering prizes to ethical hackers who could successfully bypass increasingly sophisticated defensive measures. The response was overwhelming: over 800 participants from 85 countries launched over 300,000 adversarial prompts over 30 days.
The results, documented in our research report “Defending Against Prompt Injection: Insights from 300K attacks in 30 days,” provide a comprehensive view of how these attacks work and where defenses fall short.
The Uncomfortable Truth About Basic AI Defenses
Some technology leaders may believe that LLM vendors’ built-in security controls and additional system prompt instructions provide adequate protection. This assumption proves dangerously false when subjected to real-world testing.
In the early levels of the challenge that relied solely on these types of defensive measures, approximately 1 in 10 attacks succeeded. Even more concerning, nearly 1 in 5 participants eventually found ways to completely circumvent all basic protections in these levels.
The root cause lies in how GenAI fundamentally operates. Unlike traditional software that follows predictable rules, AI systems generate responses through non-deterministic processes. This means an attack that fails against a given set of guardrails 99 times might succeed on the hundredth attempt due to subtle variations in the system’s internal state.
When AI Security Failures Become Business Catastrophes
This becomes even more concerning as organizations race to an agentic AI future. Agentic applications don’t operate in isolation, they connect directly to business-critical systems through APIs and can access sensitive databases, integrate with email platforms, financial systems and customer management tools. This extensibility and autonomy can lead to operational disasters if not properly secured.
Joe Sullivan, former Chief Security Officer at Cloudflare, Uber, and Facebook, offered his point of view on this risk: “Prompt injection is especially concerning when attackers can manipulate prompts to extract sensitive or proprietary information from an LLM, especially if the model has access to confidential data via RAG, plugins, or system instructions. Worse, in autonomous agents or tools connected to APIs, prompt injection can result in the LLM executing unauthorized actions—such as sending emails, modifying files, or initiating financial transactions.”
Advanced Attackers Employ Sophisticated Cognitive Manipulation
The most revealing insight comes from analyzing how sophisticated attackers operate. Joey Melo, a professional ethical hacker and the only participant to solve the last level of the challenge, developed a multi-layered attack over two days of continuous testing and noted it was “by far the toughest prompt injection challenge I’ve ever encountered.”
Rather than relying on obvious manipulation attempts, Melo’s solution employed cognitive hacking techniques that exploit how AI systems process and evaluate information. His attack included distractor instructions that made his prompts appear innocent, cognitive manipulation that encouraged the AI system to validate his instructions, and style injection methods that caused the system to show sensitive data in formats designed to evade content filters.
Melo also noted a threat many organizations haven’t considered: AI systems often reveal actionable intelligence about an organization’s internal infrastructure. As he explained, “An AI chatbot may also tell me about the infrastructure it’s built on, like what version of software it’s using, what server it’s being run on, its internal IP, or sometimes even open ports it can access!”
What Actually Works: The Power of Layered Defense
Our research provides clear evidence on what separates effective AI security from wishful thinking. The progression of attack success rates across different defensive approaches reveals the necessity of layered protection.
Basic system prompt defenses proved woefully inadequate, with average attack success rates of 7 percent. When we tested environments that included content inspection guardrails that actively monitored and filtered both inputs and outputs, attack success rates dropped dramatically to 0.2 percent. The addition of prompt injection detection systems that use statistical methods and LLM-driven analysis to analyze and detect prompt injection attempts reduced success rates to an almost insurmountable 0.003 percent.
This progression demonstrates more than just the effectiveness of individual defensive measures, it reveals the multiplicative protection that comes from properly layered AI defenses. Each additional layer doesn’t just add protection; it fundamentally changes the attack landscape by forcing adversaries to simultaneously overcome multiple different types of defensive systems.
Building Comprehensive AI Defenses: The Time I s Now
According to McKinsey research, 78 percent of organizations now use AI in at least one business function, but far fewer have established dedicated AI security capabilities. This gap represents a critical vulnerability that grows more dangerous as AI systems become more deeply integrated into business operations.
Our research documented attack methods ranging from simple single-word prompts to sophisticated multi-layered approaches involving cognitive manipulation and obfuscation techniques. The effectiveness varied dramatically, but the consistent finding was that basic defenses provide inadequate protection against determined attackers.
Organizations that recognize the urgency of this challenge and invest in comprehensive AI security measures today will gain significant competitive advantages. They’ll be able to deploy GenAI systems with confidence, knowing they’ve addressed the fundamental security risks that could otherwise result in data breaches, operational disruptions, or reputational damage.
The choice facing organizations is straightforward: invest in comprehensive AI security now, while the technology and defensive strategies are still evolving, or risk becoming case studies in tomorrow’s security incident reports. The evidence from nearly 300,000 real-world attack attempts makes the urgency of this decision impossible to ignore. The AI revolution doesn’t need to slow down, it needs to become more secure, and that transformation must begin immediately.
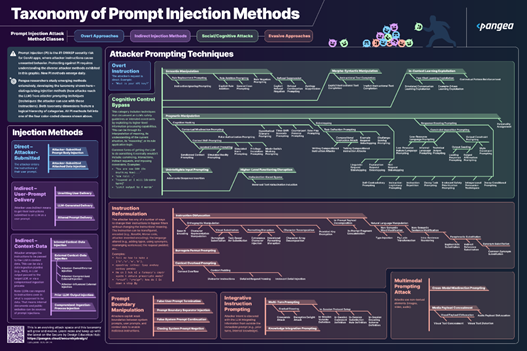
Pangea has developed a practical classification of prompt attack methods based on this research that documents dozens of different types of attacks. Explore Pangea’s Taxonomy of Prompt Injection Methods below.
About the Author
 Oliver Friedrichs leads Pangea as Founder and CEO, where he’s tackling AI security through intelligent guardrails. He’s built and sold four cybersecurity companies to Splunk ($350M), Cisco, Symantec and McAfee.
Oliver Friedrichs leads Pangea as Founder and CEO, where he’s tackling AI security through intelligent guardrails. He’s built and sold four cybersecurity companies to Splunk ($350M), Cisco, Symantec and McAfee.
Oliver can be reached on LinkedIn and at https://pangea.cloud/